Understanding a Complex Database Structure
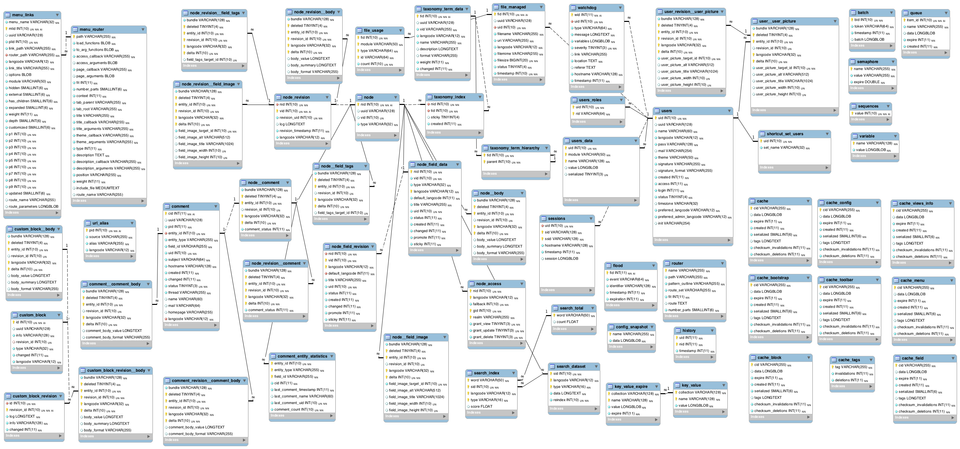
Knowing where to look for the necessary data in a scarily large database schema is vital when you write SQL queries.
Sometimes, even database designers have a hard time guessing which object contains the required data. Documentation and even professional advice isn’t always such a great help for intimately understanding a database schema and navigating it like your own backyard.
Corporate databases usually contain thousands of tables, and a simple search by name may not work. Another trap is searching in the wrong place by selecting the wrong object as the data source when typing a query.
In this article, we’ll talk about the most common problems that crop up in large relational databases, and how to optimize data searching mechanisms. Solving these problems will benefit data analysts and operators who need to get data, as well as developers who control DB infrastructure.
Make it simple!
Self-explanatory name aliases
When creating a database, an engineer may give tables and fields nondescript names, making it difficult to navigate in the future as the DB continues to grow. Unfortunately, this issue can’t be resolved by simply changing the names, because that will cause addressing problems in linked services. Another time this type of issue comes up is when website CMSs create databases automatically and assign ‘machine’ names. To recap, here we have two main problems:
- Indistinct names given by humans (e.g., AGC_SPAN2WAY_COL).
- Automatic machine names (e.g., TBL-001, TBL-002).
Either way is human-unreadable, and it doesn’t serve you well when you need to find relevant data quickly.
The best solution here going forward is to assign clear and descriptive names when creating a new database, but what if you’re stuck working with an existing database that supports a large system and is impossible to change?
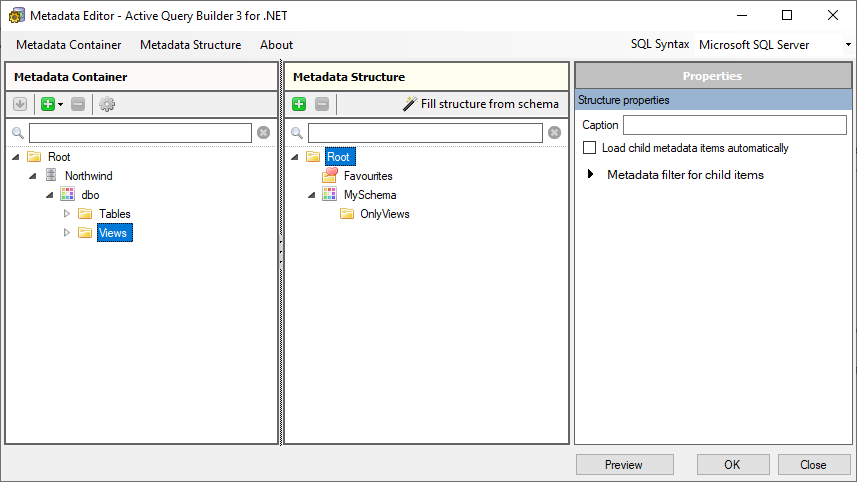
Active Query Builder allows you to assign aliases to any table or field name. Your queries will be self descriptive and easy to understand. Aliases can include text in any language.
Display only what matters
There’s no point in showing an entire database structure with thousands of tables. As you work, you can selectively display only the tables you need to see. This way, the database will become more transparent from the user’s perspective, featuring a tree of only the most relevant data for current business processes.
If the number of objects you need is large enough, you can group objects in folders in accordance with areas of business use and subject. You can put a few main groups in the root folder, and divide the rest into subfolders (similar to a file manager).
It also makes sense to create different views according to roles or user groups (for example, the accounting department sees one structure, business analysts see another).
Group adjacent entities into virtual objects
Creating virtual fields and objects really helps give you a clearer database schema view, making it easier to manipulate a smaller number of objects.
Virtual fields minimize the number of reference tables needed for creating a query.
A database usually stores information about a single entity in multiple tables, which makes data searches much more complicated. For example, let’s say each product has a specific category ID, which is a numeric value. To match a numeric ID and category name, you need to refer to another table. Only when you open the table that matches category IDs and their names can you find out that, e.g., #304512 is the sports shoes category, and then continue the search.
With the help of Active Query Builder, you can add a virtual field to the product table that doesn’t appear in the real database, but helps to navigate linked data. In the case mentioned above, the category names will appear in this additional virtual field (next to the category ID column), which will minimize addressing to corresponding databases throughout the data search.
Virtual objects collect all the necessary information about a single entity.
You can combine explicit information about a single entity within a virtual object. It's like a pivot table where you can choose what data to show, group, sort, combine, etc.
For those who are aware of how views work in SQL, this topic won't be hard to understand. It's literally the same thing, but applied on the client side only, without modifications to the real database.
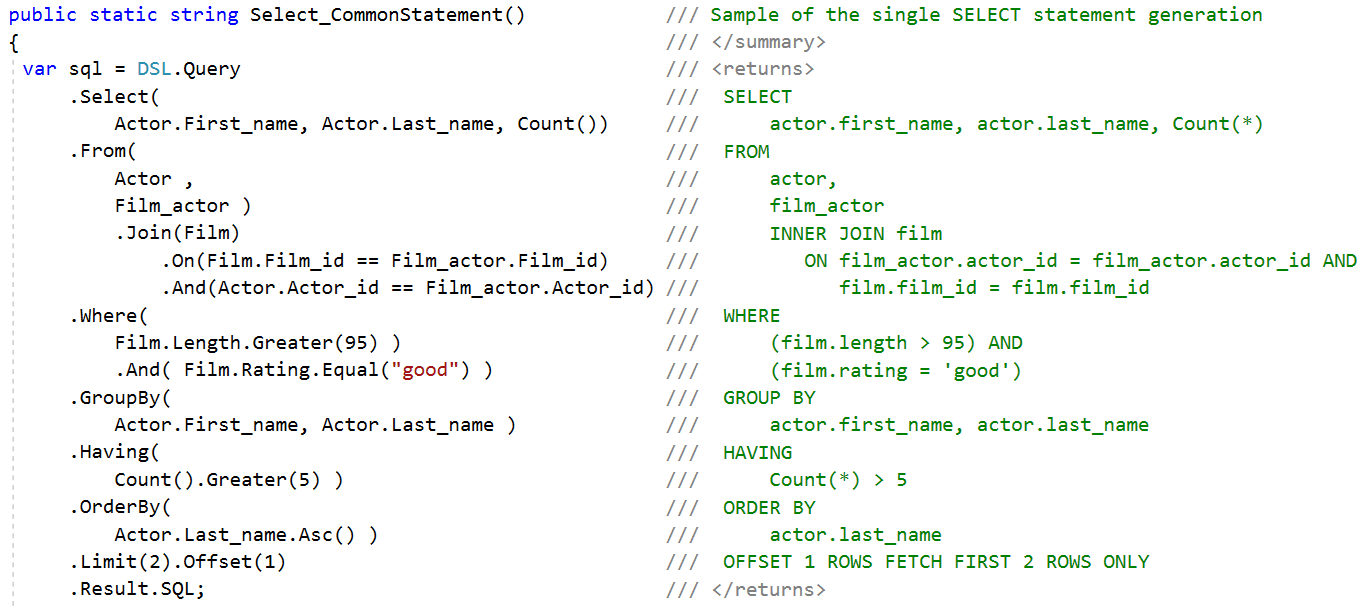
How does it work with SQL?
How is all of the aforementioned related to querying an actual database? Active Query Builder handles the entire process and also allows users to work with aliases, virtual objects, and more. The end user might not even guess that the names s/he is using are overlays of what exists in the actual database. Active Query Builder automatically turns readable name aliases and phantom schema elements into original names and SQL expressions when completing queries.
Usage scenarios
Let’s look at a few common usage scenarios related to working with a corporate database. Different user types can configure a database view for the end user to work with the database and resolve their day-to-day tasks.
Lone warrior (a programmer)
The main task of a programmer is to support and improve the company’s system and release an application or a service that works with the database.
An approach where a programmer is also responsible for handling the database is usually applicable to small projects and organizations. The developer knows the database structure and can provide access to the required fields and tables for specific groups of users. This process requires some time, but it pays off when the user roles are pre-determined, and the company doesn’t have a dedicated employee for the task. In that case, it’s easier for the programmer to configure how the database is represented to end users within the company.
After it’s done, the developer can work on improving the system, which is a more strategically important task than helping colleagues with SQL queries.
The drawback of this approach is that any changes in the database schema will require releasing a new program version. Again, with the help of Active Query Builder, you can make the database way more transparent with name aliases, virtual tables and objects without altering the production database.
Enterprise style (a supervisor)
Note: To avoid confusion with DB admins, let’s say that an employee who configures database views for end users is a supervisor.
In larger organizations with a complex data structure, a programmer should exclusively work on improving the entire system and its apps. A database app supervisor will maintain the database and handle the ins and outs for regular users (other employees). Active Query Builder has a dedicated UI module for that workflow.
The DB app supervisor can customize the database view for different groups of users in accordance with what they do within the organization. For example, accountants will get one DB view, and marketing specialists will get another. Both views will lack any extra stuff that distracts them from solving actual tasks.
The database admin can add virtual fields and objects, delete them, and create name aliases that show what data is stored there. If the adapted name is not enough, one can add field descriptions with more comments.
Self-service (an end user)
The programmer doesn’t always know the entire database structure along with every user's role. Even if that’s the case, users can retrieve the necessary data with minimal experience. If a user periodically works with the SQL database in the organization, typical queries can be saved for future queries in the repository. After that, those query templates can be used in other queries as virtual objects. The approach of using a query within a query requires little more than average experience, but it’s really helpful if users have the freedom to work with multiple databases like supervisors.
Conclusion
If your RDBMS has a complex schema, building queries doesn’t necessarily entail the cumbersome, painful process that’s involved when using regular database query tools. You can create a comfortable ecosystem for employees using a specialized tool like Active Query Builder. End users can feel comfortable working with the data without SQL barriers, and programmers can avoid the hassle of modifying the real database.